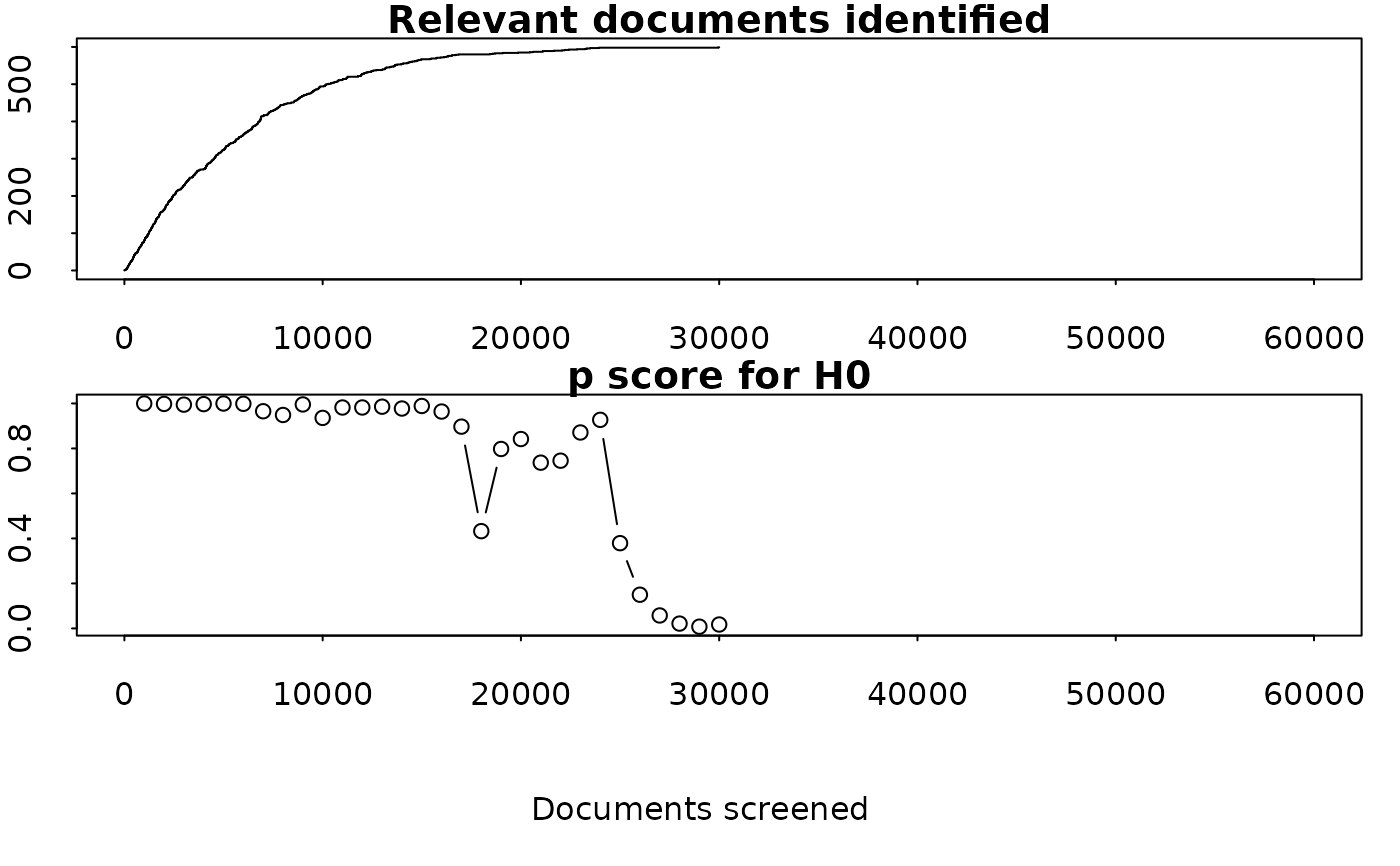
Calculate retrospective H0
retrospective_h0.RdCalculates p scores for our null hypothesis H0, every `batch_size` documents of the documents we have already screened, and plot a graph these p scores, alongside the curve showing the number of relevant documents identified.
Arguments
- df
A data.frame that contains the columns `relevant` and `seen` The dataframe should have as many rows as there are documents, and be ordered in the order dictated by the ML prioritisation algorithm. relevant should contain 1s and 0s for relevant and irrelevant documents, and NAs for documents that have not yet been screened. Seen should contain 1s where documents have been screened by a human, and 0s where documents have not yet been screened
- recall_target
The recall target (default=0.95). Must be between 0 and 1
- bias
a number which represents our estimate of how much more likely we were to select a random relevant document than a random irrelevant document. The higher this is, the better we think the machine learning went.
- batch_size
The p score will calculated every `batch_size` documents. Smaller batches will result in greater granularity but larger computation time (default=1000).
- plot
Boolean describing whether to plot a graph (default=True).
Value
A dataframe with a column `p` showing the p score for h0 calculated at number of screened documents in column `seen`
Examples
N <- 60000 # number of documents
prevalence <- 0.01 # prevalence of relevant documents
r <- N*0.01 # number of relevant documents
bias <- 10
docs <- rep(0,N)
docs[1:r] <- 1
weights = rep(1,N)
weights[1:r] <- bias
set.seed(2023)
docs <- sample(
docs, prob=weights, replace=F
)
df <- data.frame(relevant=docs)
df$seen <- 0
df$seen[1:30000] <- 1
h0_df <- retrospective_h0(df)